Here we will have to work with the experiment data we collected for this class.
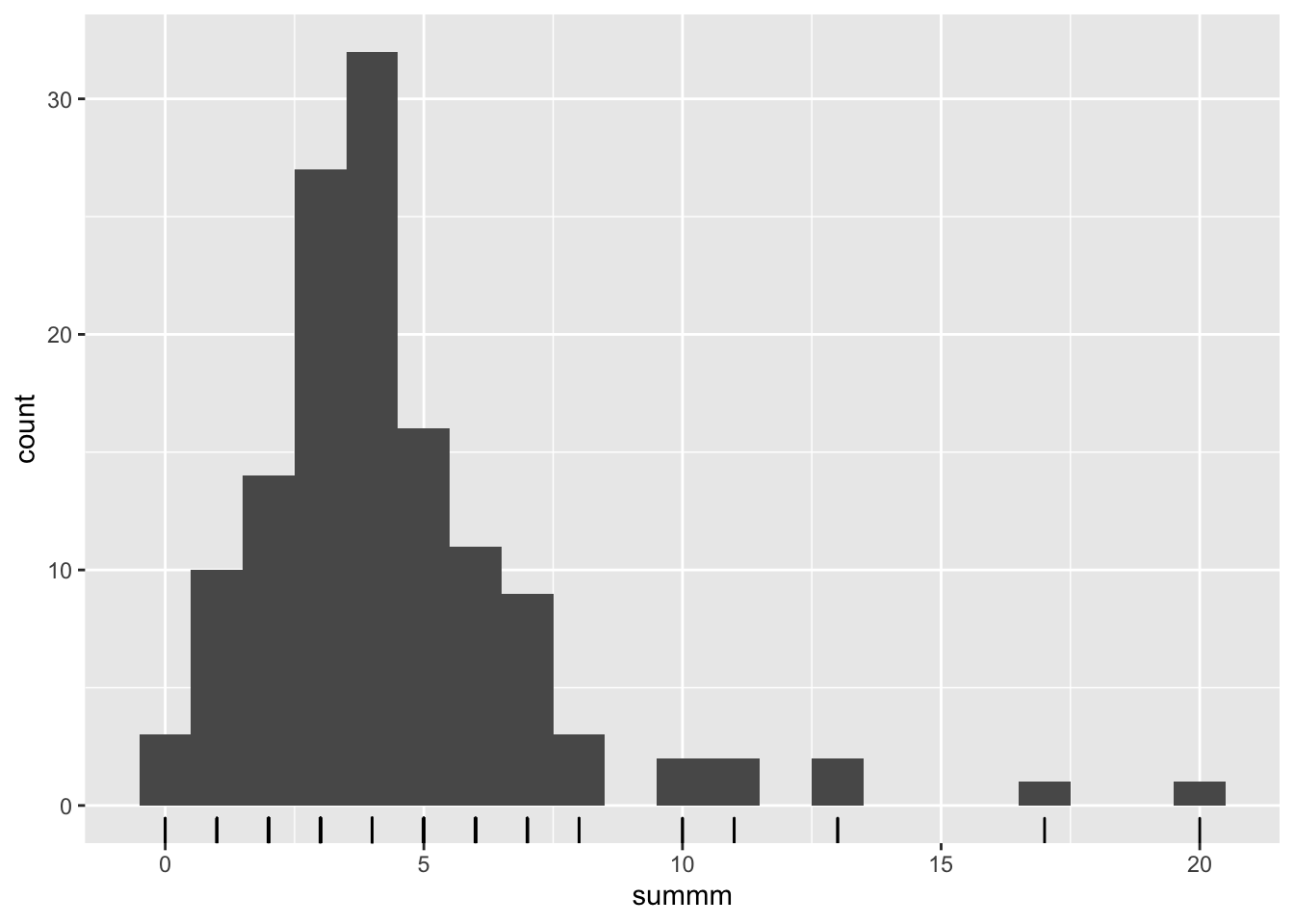
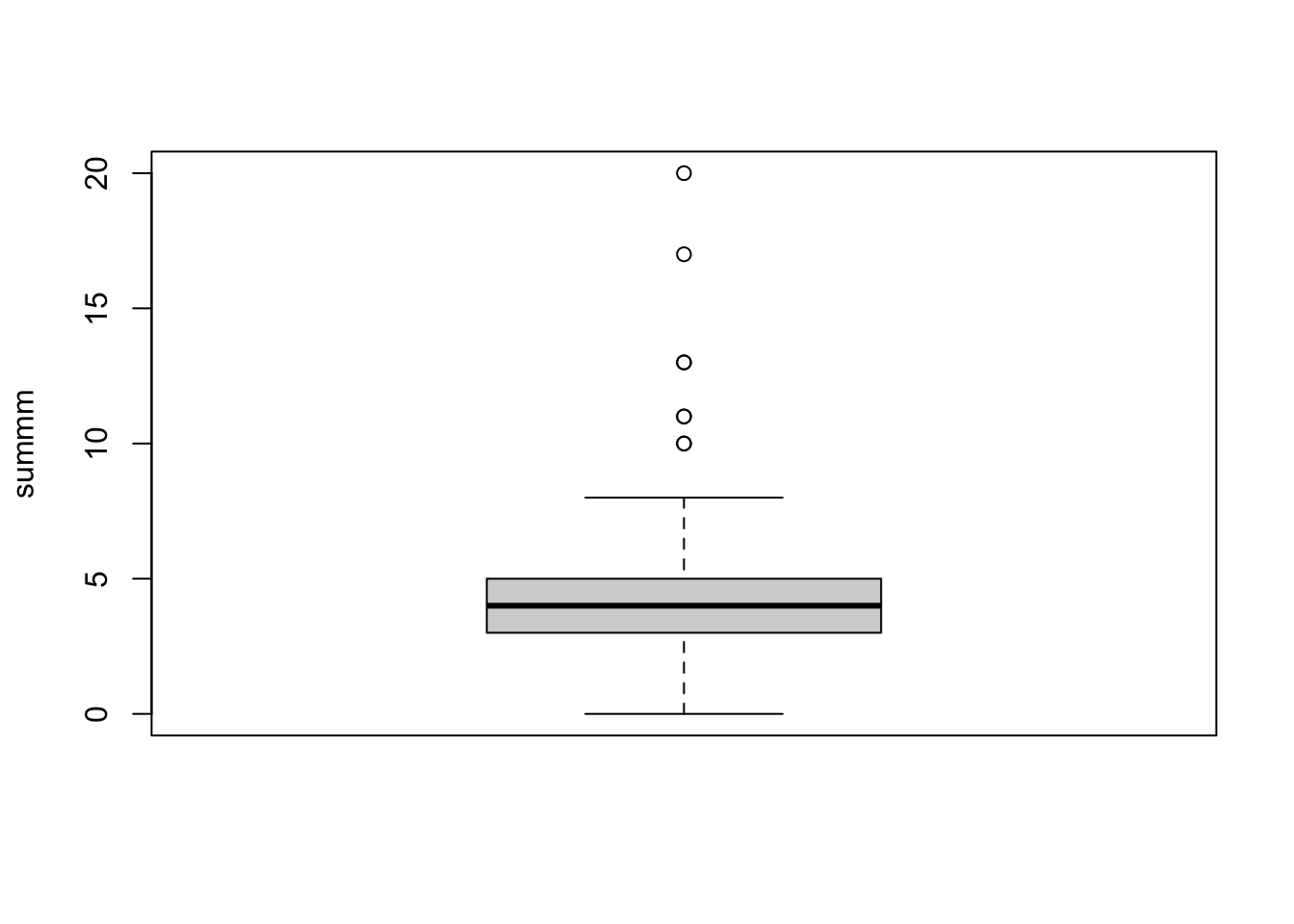
We are interested in whether some people were more likely to make correct guesses. What are the summary statistics for all draws? Plot a histogram. Are there any outliers in the data (i.e. individuals who guess 0 times correctly and individuals who guessed all 20 times correctly?)
we draw a histogram based on the summary statistics. To find
We use pivot longer once more in order to have all the observations in one column. Having the observations in one column, is easier for us to group by the id column we created before. So we groupby id. This helps us identify what each person done. In addition, we add a column using mutate in order to have the clear result of each person.
pi <- pilpi %>%pivot_longer(cols =starts_with("Outcome"), names_to="draw", values_to ="answer") %>%group_by(id) ti<- pi %>%mutate(summm=sum(answer))tii<- pi %>%mutate(summm=sum(answer)) %>%separate(draw, into =c("rolsep", "rolnum"), sep ="e") %>%group_by(id)# boxplot.stats(data$score)$out# # rr <- ti %>% separate(draw, into = c("rolsep", "rolnum"), sep = "e") %>% group_by(id, rolnum)
Now we pivot wider once more so the data can be presented in the form that shows how people are doing from the 1st one until the last (133rd).
final <- ti %>%pivot_wider(id_cols =c(id, Age, SC0, Risk, Gender, summm), names_from = draw, values_from = answer)# finally <- tii %>% pivot_wider(id_cols = c(id, Age, SC0, Risk, Gender, summm), names_from = rolnum, values_from = answer)# # fin <- final %>% inner_join(ex22, by = "id")
Analyze the data by gender, the draw number, and by experimental condition. Are there differences between the genders in terms of the number of wins versus losses? Are there differences between the experimental conditions? Are people more or less likely to win towards the last draws as opposed to the beginning of the experiment?
‘Final’ is the column that already has everything needed for the analysis. The only missing column is conditions. To do that, I used mutate to create a new column named as condition where each real condition is named after a number from one to five. I also create an id column in the ex2 dataset so I can then inner_join it with our main column.
At this point, I create a new dataset with ‘id’ and ‘condition’ columns so it is easier to inner_join them. Then I inner_join them so I have everything in one dataset named ‘fin’.
ex22 <- ex2 %>%select(id, condition, rolnum)fin <- final %>%inner_join(ex22, by ="id")
Then we group by Gender and summarise by mean. This allows us to see the mean score that each gender got correct. As we can see, females reported a higher correct score than males on average.
fin %>%group_by(Gender) %>%summarise(mean(summm))
# A tibble: 2 × 2
Gender `mean(summm)`
<chr> <dbl>
1 Female 4.75
2 Male 3.68
# mutate(rrr, coun)# fin %>% group_by(condition) %>% summarise(mean(summm))
Analyzing the data regarding the draw number we use the tii dataset. The reason is because this dataset was created in question 1 with a function named seperate. This function separated the column ‘draw’ into two others (rolsep, rolsum). The first stands for the title of the draw column while the second one stands for the values that a correct answer was reported.
Therefore, we here use the filter column(rolnum) equal with the number of observation we want piped with summary(answer). This helps us find the stats behind the correct answers in each round. Also, we named a new dataset ‘i’ where it excludes some irrelevant columns for the purpose of analyzing the data based on draws.
Regarding the draws we can see that the mean for outcome number 1 is almost 20% (0.1955). That means that one out of five people reported a correct answer in that case. As we can see the mean of correct responses ranges from 0.16 to 0.27. This means that the standard deviation is relatively low. In other words all correct response rates are clustered around the mean.
id rolnum answer
Min. : 1 Length:133 Min. :0.0000
1st Qu.: 34 Class :character 1st Qu.:0.0000
Median : 67 Mode :character Median :0.0000
Mean : 67 Mean :0.1955
3rd Qu.:100 3rd Qu.:0.0000
Max. :133 Max. :1.0000
i %>%filter(rolnum==2) %>%summary(answer)
id rolnum answer
Min. : 1 Length:133 Min. :0.0000
1st Qu.: 34 Class :character 1st Qu.:0.0000
Median : 67 Mode :character Median :0.0000
Mean : 67 Mean :0.2406
3rd Qu.:100 3rd Qu.:0.0000
Max. :133 Max. :1.0000
i %>%filter(rolnum==3) %>%summary(answer)
id rolnum answer
Min. : 1 Length:133 Min. :0.0000
1st Qu.: 34 Class :character 1st Qu.:0.0000
Median : 67 Mode :character Median :0.0000
Mean : 67 Mean :0.1654
3rd Qu.:100 3rd Qu.:0.0000
Max. :133 Max. :1.0000
i %>%filter(rolnum==4) %>%summary(answer)
id rolnum answer
Min. : 1 Length:133 Min. :0.0000
1st Qu.: 34 Class :character 1st Qu.:0.0000
Median : 67 Mode :character Median :0.0000
Mean : 67 Mean :0.1654
3rd Qu.:100 3rd Qu.:0.0000
Max. :133 Max. :1.0000
i %>%filter(rolnum==5) %>%summary(answer)
id rolnum answer
Min. : 1 Length:133 Min. :0.0000
1st Qu.: 34 Class :character 1st Qu.:0.0000
Median : 67 Mode :character Median :0.0000
Mean : 67 Mean :0.2331
3rd Qu.:100 3rd Qu.:0.0000
Max. :133 Max. :1.0000
i %>%filter(rolnum==6) %>%summary(answer)
id rolnum answer
Min. : 1 Length:133 Min. :0.0000
1st Qu.: 34 Class :character 1st Qu.:0.0000
Median : 67 Mode :character Median :0.0000
Mean : 67 Mean :0.2556
3rd Qu.:100 3rd Qu.:1.0000
Max. :133 Max. :1.0000
i %>%filter(rolnum==7) %>%summary(answer)
id rolnum answer
Min. : 1 Length:133 Min. :0.000
1st Qu.: 34 Class :character 1st Qu.:0.000
Median : 67 Mode :character Median :0.000
Mean : 67 Mean :0.203
3rd Qu.:100 3rd Qu.:0.000
Max. :133 Max. :1.000
i %>%filter(rolnum==8) %>%summary(answer)
id rolnum answer
Min. : 1 Length:133 Min. :0.0000
1st Qu.: 34 Class :character 1st Qu.:0.0000
Median : 67 Mode :character Median :0.0000
Mean : 67 Mean :0.1955
3rd Qu.:100 3rd Qu.:0.0000
Max. :133 Max. :1.0000
i %>%filter(rolnum==9) %>%summary(answer)
id rolnum answer
Min. : 1 Length:133 Min. :0.0000
1st Qu.: 34 Class :character 1st Qu.:0.0000
Median : 67 Mode :character Median :0.0000
Mean : 67 Mean :0.2406
3rd Qu.:100 3rd Qu.:0.0000
Max. :133 Max. :1.0000
i %>%filter(rolnum==10) %>%summary(answer)
id rolnum answer
Min. : 1 Length:133 Min. :0.0000
1st Qu.: 34 Class :character 1st Qu.:0.0000
Median : 67 Mode :character Median :0.0000
Mean : 67 Mean :0.2105
3rd Qu.:100 3rd Qu.:0.0000
Max. :133 Max. :1.0000
i %>%filter(rolnum==11) %>%summary(answer)
id rolnum answer
Min. : 1 Length:133 Min. :0.000
1st Qu.: 34 Class :character 1st Qu.:0.000
Median : 67 Mode :character Median :0.000
Mean : 67 Mean :0.203
3rd Qu.:100 3rd Qu.:0.000
Max. :133 Max. :1.000
i %>%filter(rolnum==12) %>%summary(answer)
id rolnum answer
Min. : 1 Length:133 Min. :0.0000
1st Qu.: 34 Class :character 1st Qu.:0.0000
Median : 67 Mode :character Median :0.0000
Mean : 67 Mean :0.1955
3rd Qu.:100 3rd Qu.:0.0000
Max. :133 Max. :1.0000
i %>%filter(rolnum==13) %>%summary(answer)
id rolnum answer
Min. : 1 Length:133 Min. :0.0000
1st Qu.: 34 Class :character 1st Qu.:0.0000
Median : 67 Mode :character Median :0.0000
Mean : 67 Mean :0.1955
3rd Qu.:100 3rd Qu.:0.0000
Max. :133 Max. :1.0000
i %>%filter(rolnum==14) %>%summary(answer)
id rolnum answer
Min. : 1 Length:133 Min. :0.0000
1st Qu.: 34 Class :character 1st Qu.:0.0000
Median : 67 Mode :character Median :0.0000
Mean : 67 Mean :0.2707
3rd Qu.:100 3rd Qu.:1.0000
Max. :133 Max. :1.0000
i %>%filter(rolnum==15) %>%summary(answer)
id rolnum answer
Min. : 1 Length:133 Min. :0.0000
1st Qu.: 34 Class :character 1st Qu.:0.0000
Median : 67 Mode :character Median :0.0000
Mean : 67 Mean :0.2556
3rd Qu.:100 3rd Qu.:1.0000
Max. :133 Max. :1.0000
i %>%filter(rolnum==16) %>%summary(answer)
id rolnum answer
Min. : 1 Length:133 Min. :0.0000
1st Qu.: 34 Class :character 1st Qu.:0.0000
Median : 67 Mode :character Median :0.0000
Mean : 67 Mean :0.2556
3rd Qu.:100 3rd Qu.:1.0000
Max. :133 Max. :1.0000
i %>%filter(rolnum==17) %>%summary(answer)
id rolnum answer
Min. : 1 Length:133 Min. :0.0000
1st Qu.: 34 Class :character 1st Qu.:0.0000
Median : 67 Mode :character Median :0.0000
Mean : 67 Mean :0.2256
3rd Qu.:100 3rd Qu.:0.0000
Max. :133 Max. :1.0000
i %>%filter(rolnum==18) %>%summary(answer)
id rolnum answer
Min. : 1 Length:133 Min. :0.0000
1st Qu.: 34 Class :character 1st Qu.:0.0000
Median : 67 Mode :character Median :0.0000
Mean : 67 Mean :0.2105
3rd Qu.:100 3rd Qu.:0.0000
Max. :133 Max. :1.0000
i %>%filter(rolnum==19) %>%summary(answer)
id rolnum answer
Min. : 1 Length:133 Min. :0.000
1st Qu.: 34 Class :character 1st Qu.:0.000
Median : 67 Mode :character Median :0.000
Mean : 67 Mean :0.218
3rd Qu.:100 3rd Qu.:0.000
Max. :133 Max. :1.000
i %>%filter(rolnum==20) %>%summary(answer)
id rolnum answer
Min. : 1 Length:133 Min. :0.0000
1st Qu.: 34 Class :character 1st Qu.:0.0000
Median : 67 Mode :character Median :0.0000
Mean : 67 Mean :0.2632
3rd Qu.:100 3rd Qu.:1.0000
Max. :133 Max. :1.0000
Regarding the experimental condition of the data, we use the groupby function to call it in the fin dataset, and then use summarise to find the mean. Alongside, as we set above, each number corresponds in one condition. As we can see, the most popular experimental condition is normative positive message (2) while the least popular is empirical positive message (5).
fin %>%group_by(condition) %>%summarise(mean(summm))
Redo part 2 after excluding outliers. Do you still see the different in the experimental groups after outliers are eliminated? Do you see differences between the first and the last rolls? Are there any differences by gender?
Redoing exercise 2 with the new dataframe ‘desperate’.
In comparison with exercise 2, we can see that the mean for both male and female has fallen. This was a natural outcome to follow since the outliers were all above the mean. However, the outcome remained the same in matters of which gender reported the most correct answers. On average females report 4 correct answers out of twenty, as opposed to men (3/20).
# A tibble: 2 × 2
Gender `mean(summm)`
<chr> <dbl>
1 Female 4.19
2 Male 3.14
For the draws, we are creating a new column to make the analysis named ‘abcdefg’. This is to exclude the outlier rows from the the ‘tii’ dataset we’ve used at exercise 2. After doing that though, we can see that the mean correct response reporting ratio remained at the same levels ranging from 16.54% to 27.07%. This indicates that the outliers did not affect the variability of the data. No difference between the first and last rows.
id rolnum answer
Min. : 1.00 Length:132 Min. :0.000
1st Qu.: 34.75 Class :character 1st Qu.:0.000
Median : 67.50 Mode :character Median :0.000
Mean : 67.45 Mean :0.197
3rd Qu.:100.25 3rd Qu.:0.000
Max. :133.00 Max. :1.000
i %>%filter(rolnum==2) %>%summary(answer)
id rolnum answer
Min. : 1 Length:133 Min. :0.0000
1st Qu.: 34 Class :character 1st Qu.:0.0000
Median : 67 Mode :character Median :0.0000
Mean : 67 Mean :0.2406
3rd Qu.:100 3rd Qu.:0.0000
Max. :133 Max. :1.0000
i %>%filter(rolnum==3) %>%summary(answer)
id rolnum answer
Min. : 1 Length:133 Min. :0.0000
1st Qu.: 34 Class :character 1st Qu.:0.0000
Median : 67 Mode :character Median :0.0000
Mean : 67 Mean :0.1654
3rd Qu.:100 3rd Qu.:0.0000
Max. :133 Max. :1.0000
i %>%filter(rolnum==4) %>%summary(answer)
id rolnum answer
Min. : 1 Length:133 Min. :0.0000
1st Qu.: 34 Class :character 1st Qu.:0.0000
Median : 67 Mode :character Median :0.0000
Mean : 67 Mean :0.1654
3rd Qu.:100 3rd Qu.:0.0000
Max. :133 Max. :1.0000
i %>%filter(rolnum==5) %>%summary(answer)
id rolnum answer
Min. : 1.00 Length:132 Min. :0.0000
1st Qu.: 34.75 Class :character 1st Qu.:0.0000
Median : 67.50 Mode :character Median :0.0000
Mean : 67.49 Mean :0.2348
3rd Qu.:100.25 3rd Qu.:0.0000
Max. :133.00 Max. :1.0000
i %>%filter(rolnum==6) %>%summary(answer)
id rolnum answer
Min. : 1 Length:133 Min. :0.0000
1st Qu.: 34 Class :character 1st Qu.:0.0000
Median : 67 Mode :character Median :0.0000
Mean : 67 Mean :0.2556
3rd Qu.:100 3rd Qu.:1.0000
Max. :133 Max. :1.0000
i %>%filter(rolnum==7) %>%summary(answer)
id rolnum answer
Min. : 1 Length:133 Min. :0.000
1st Qu.: 34 Class :character 1st Qu.:0.000
Median : 67 Mode :character Median :0.000
Mean : 67 Mean :0.203
3rd Qu.:100 3rd Qu.:0.000
Max. :133 Max. :1.000
i %>%filter(rolnum==8) %>%summary(answer)
id rolnum answer
Min. : 1.00 Length:132 Min. :0.000
1st Qu.: 34.75 Class :character 1st Qu.:0.000
Median : 67.50 Mode :character Median :0.000
Mean : 67.48 Mean :0.197
3rd Qu.:100.25 3rd Qu.:0.000
Max. :133.00 Max. :1.000
i %>%filter(rolnum==9) %>%summary(answer)
id rolnum answer
Min. : 1.00 Length:132 Min. :0.0000
1st Qu.: 34.75 Class :character 1st Qu.:0.0000
Median : 67.50 Mode :character Median :0.0000
Mean : 67.47 Mean :0.2348
3rd Qu.:100.25 3rd Qu.:0.0000
Max. :133.00 Max. :1.0000
i %>%filter(rolnum==10) %>%summary(answer)
id rolnum answer
Min. : 1.00 Length:132 Min. :0.0000
1st Qu.: 34.75 Class :character 1st Qu.:0.0000
Median : 67.50 Mode :character Median :0.0000
Mean : 67.45 Mean :0.2121
3rd Qu.:100.25 3rd Qu.:0.0000
Max. :133.00 Max. :1.0000
i %>%filter(rolnum==11) %>%summary(answer)
id rolnum answer
Min. : 1 Length:133 Min. :0.000
1st Qu.: 34 Class :character 1st Qu.:0.000
Median : 67 Mode :character Median :0.000
Mean : 67 Mean :0.203
3rd Qu.:100 3rd Qu.:0.000
Max. :133 Max. :1.000
i %>%filter(rolnum==12) %>%summary(answer)
id rolnum answer
Min. : 1 Length:133 Min. :0.0000
1st Qu.: 34 Class :character 1st Qu.:0.0000
Median : 67 Mode :character Median :0.0000
Mean : 67 Mean :0.1955
3rd Qu.:100 3rd Qu.:0.0000
Max. :133 Max. :1.0000
i %>%filter(rolnum==13) %>%summary(answer)
id rolnum answer
Min. : 1 Length:133 Min. :0.0000
1st Qu.: 34 Class :character 1st Qu.:0.0000
Median : 67 Mode :character Median :0.0000
Mean : 67 Mean :0.1955
3rd Qu.:100 3rd Qu.:0.0000
Max. :133 Max. :1.0000
i %>%filter(rolnum==14) %>%summary(answer)
id rolnum answer
Min. : 1 Length:133 Min. :0.0000
1st Qu.: 34 Class :character 1st Qu.:0.0000
Median : 67 Mode :character Median :0.0000
Mean : 67 Mean :0.2707
3rd Qu.:100 3rd Qu.:1.0000
Max. :133 Max. :1.0000
i %>%filter(rolnum==15) %>%summary(answer)
id rolnum answer
Min. : 2.00 Length:132 Min. :0.0000
1st Qu.: 34.75 Class :character 1st Qu.:0.0000
Median : 67.50 Mode :character Median :0.0000
Mean : 67.50 Mean :0.2576
3rd Qu.:100.25 3rd Qu.:1.0000
Max. :133.00 Max. :1.0000
i %>%filter(rolnum==16) %>%summary(answer)
id rolnum answer
Min. : 1 Length:133 Min. :0.0000
1st Qu.: 34 Class :character 1st Qu.:0.0000
Median : 67 Mode :character Median :0.0000
Mean : 67 Mean :0.2556
3rd Qu.:100 3rd Qu.:1.0000
Max. :133 Max. :1.0000
i %>%filter(rolnum==17) %>%summary(answer)
id rolnum answer
Min. : 1.00 Length:132 Min. :0.0000
1st Qu.: 34.75 Class :character 1st Qu.:0.0000
Median : 67.50 Mode :character Median :0.0000
Mean : 67.48 Mean :0.2273
3rd Qu.:100.25 3rd Qu.:0.0000
Max. :133.00 Max. :1.0000
i %>%filter(rolnum==18) %>%summary(answer)
id rolnum answer
Min. : 1.00 Length:132 Min. :0.0000
1st Qu.: 34.75 Class :character 1st Qu.:0.0000
Median : 67.50 Mode :character Median :0.0000
Mean : 67.47 Mean :0.2045
3rd Qu.:100.25 3rd Qu.:0.0000
Max. :133.00 Max. :1.0000
i %>%filter(rolnum==19) %>%summary(answer)
id rolnum answer
Min. : 1 Length:133 Min. :0.000
1st Qu.: 34 Class :character 1st Qu.:0.000
Median : 67 Mode :character Median :0.000
Mean : 67 Mean :0.218
3rd Qu.:100 3rd Qu.:0.000
Max. :133 Max. :1.000
i %>%filter(rolnum==20) %>%summary(answer)
id rolnum answer
Min. : 1 Length:133 Min. :0.0000
1st Qu.: 34 Class :character 1st Qu.:0.0000
Median : 67 Mode :character Median :0.0000
Mean : 67 Mean :0.2632
3rd Qu.:100 3rd Qu.:1.0000
Max. :133 Max. :1.0000
In the case of experimental conditions we can see that there are some significant differences. The range between them became smaller (3.36 to 4.69). In other words the data became more disperse. While there is no difference in the lower end, there is a difference in the higher end of the range. This indicates that the previous means were inflated due to the high outliers. For insance, the most popular experimental condition, normative positive message (2), was 6.08, whereas now is just 4.33.
Split your sample into the "younger" half and the "older half. Are there differences between the two age groups?
First we sort the date from highest to lowest reported age using the order function.
ordered<- fin[order(fin$Age, decreasing =TRUE), ]
Then we find the Age median from fin dataset. As we can see, the median is 24 (in the column 67 since is exactly the middle of 133).
median(fin$Age)
[1] 24
Since I have the ordered dataframe (from the highest to lowest Age), I use it to create two other dataframes, one for the younger Age group “orderedyoung”, and one for the older Age group “orderedold”.
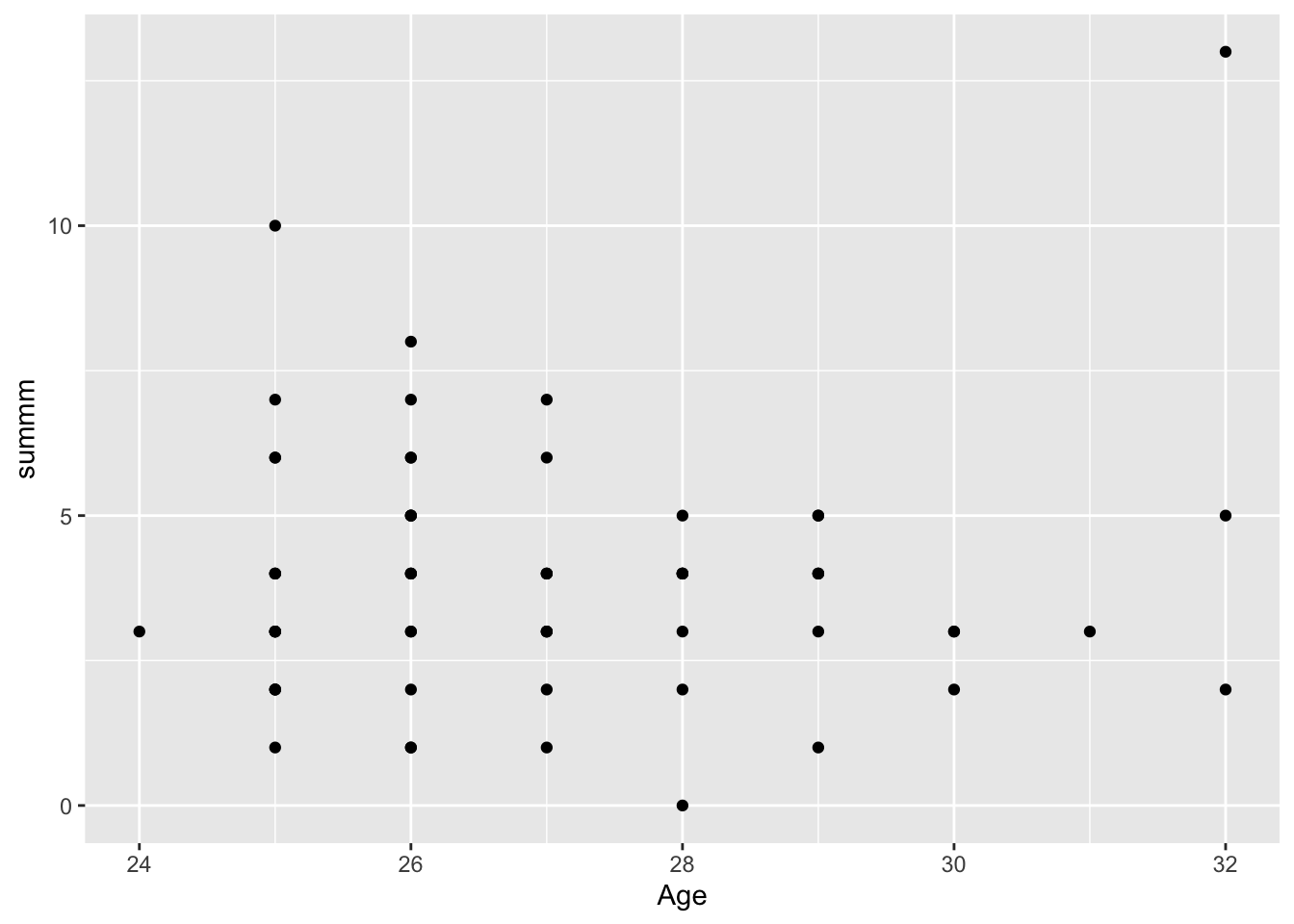
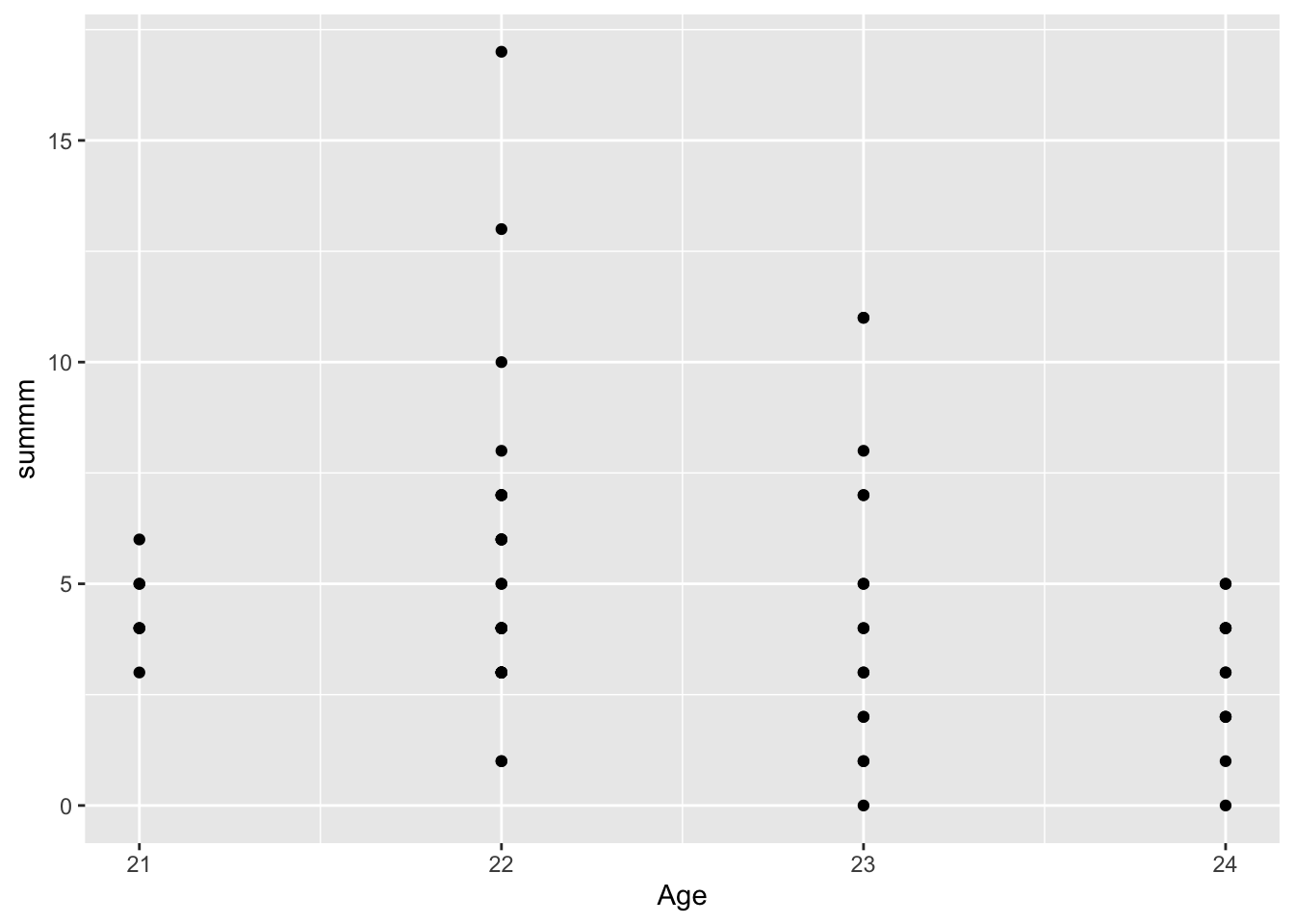
I use the ggplot function to create a graph that indicates the Age of the participants in the x axes, and the number of correct guesses (summm) in the y axes. As we can see, while the Age column now indicates only the oldest people, the majority is still under 30 – closer to the median. From the age 24 until 30s, the amount of correct responses seems to decline. We use the median and the mean code in order to see if there is a difference with them. Median indicates that there is no difference among the data as the reported correct outcome. However, if we look at the mean of the two, the younger group tends to report more correct answers on average than the older group. This difference is small though (4.62-3.92)
oo%>%ggplot(aes(x= Age, y= summm)) +geom_point()
median(oo$summm)
[1] 4
mean(oo$summm)
[1] 3.920635
oy%>%ggplot(aes(x= Age, y= summm)) +geom_point()
median(oy$summm)
[1] 4
mean(oy$summm)
[1] 4.621212
PART TWO
Let's study how the number of wins depends on certain factors:
Call:
lm(formula = score ~ Gendering, data = datacool1)
Residuals:
Min 1Q Median 3Q Max
-3.7528 -1.6818 -0.7528 0.3182 16.3182
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 4.7528 0.3088 15.389 <0.0000000000000002 ***
Gendering1 -1.0710 0.5370 -1.995 0.0482 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.914 on 131 degrees of freedom
Multiple R-squared: 0.02947, Adjusted R-squared: 0.02206
F-statistic: 3.978 on 1 and 131 DF, p-value: 0.04817
Looking at the results from the intercept and the Gendering column (1 = given that is a male), we can see that the regression equation is the following:
y=-1.07x+4.75
a) What is the effect (the slope) of gender?
To see the effect we look to the slope of x. It indicates that on average males win one time less than females.
b) How strong is the predictive power of gender?
Looking at the multiple R square we can see that the effect of gender explains 2,947% of the variability of the score.
c) What are the predicted outcomes for men and women?
For this I substitute the values for male and female on the regression equation. For male x=1, for female x=0. After doing that, we will have a result that demonstrates the predicted score for females and males given that our initial assumption holds true.
Call:
lm(formula = score ~ Age, data = datacool1)
Residuals:
Min 1Q Median 3Q Max
-4.4383 -1.4232 -0.4080 0.6524 15.4559
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 4.01507 1.36266 2.946 0.00381 **
Age 0.01511 0.05276 0.287 0.77495
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.957 on 131 degrees of freedom
Multiple R-squared: 0.0006262, Adjusted R-squared: -0.007003
F-statistic: 0.08208 on 1 and 131 DF, p-value: 0.7749
After following the same procedure as we followed in exercise 1, we have the equivalent regression results for Age as independent variable x, and score as dependent variable y. The equation is as follows:
y=0.015x+4.01
multiple R-squared, how much of the score variability is explained assuming that there is an effect of age.
a) What is the effect of age?
The effect (aka slope) of age is 0.015. This implies that there is an observed higher score of 0.015 with people that are older. Put differerently, the age factor has a negligible result to the score as is almost zero.
b) How strong is the predictive power of age?
Looking at the multiple R square we can see that the effect of age has almost zero explanation for the variability of the score. In other words, the predictive power of age on the time of victories is very weak.
c) What's the predicted outcome for a 20 year old person? For a 40 year old person?
#for 20 year oldtwentypred <-0.015*20+4.01#for 40 year oldfourtypred <-0.015*40+4.01
For this I substitute the values for 20year old and 40year old on the regression equation. For 20year x=20, for 40year old x=40. After doing that, we will have a result that demonstrates the predicted score for 20year old and 40year old given that our initial assumption holds true.
The predicted score for 20year old on average is 4.31, while the equivalent predicted score for 40year old is 4.61.
3. Examine the relationship between age and gender combined.
why the numbers are changing slightly (=men and women have different ages. when u plug both coefficients together it tries to)
a) What are the effects now? How do they compare with the results in 1 and 2? Explain the differences
Call:
lm(formula = score ~ Age + factor(Gendering), data = datacool1)
Residuals:
Min 1Q Median 3Q Max
-3.859 -1.673 -0.673 0.401 16.082
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 4.08770 1.34714 3.034 0.00291 **
Age 0.02660 0.05244 0.507 0.61280
factor(Gendering)1 -1.10062 0.54165 -2.032 0.04419 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.922 on 130 degrees of freedom
Multiple R-squared: 0.03139, Adjusted R-squared: 0.01649
F-statistic: 2.107 on 2 and 130 DF, p-value: 0.1258
Now the equation becomes:
y=0.02x1-1.1x2+4.08
with x1 being the age, and x2 being the gender given is a male (if that one is zero then is a female)
As we can see here, while the age effect is still close to zero, now it is a bit higher (0.026 as opposed to 0.015); however it still remains a weak factor. With respect to Gender, now is also higher ton the other end than its corresponding previous result (-1.10 as opposed to -1.07).
Consequently, there is a very slight inter correlation between the two factors as the model tends to become slightly stronger. How ever the differences are minimal. This is indicated also in the adjusted R squared (=0.016) which is even lower than R squared. This means that at least one of the two variables does not explain the dependent variable score. As we can see from the exercises 1 and 2, this variable is Age because its adjusted R squared is negative when we have Age as the only independent variable (see exercise 2).
Then we proceed to an interaction coefficient just to observe the cross sections between our independent variables. Despite that the numbers are changing a bit though interaction coefficient is not necessary for the purpose of this exercise.
cool3 <-lm(score~ Age *factor(Gendering), data = datacool1)summary(cool3)
Call:
lm(formula = score ~ Age * factor(Gendering), data = datacool1)
Residuals:
Min 1Q Median 3Q Max
-3.8912 -1.6606 -0.6606 0.6527 15.5740
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 5.90581 1.99661 2.958 0.00369 **
Age -0.04612 0.07890 -0.585 0.55989
factor(Gendering)1 -4.41097 2.74144 -1.609 0.11006
Age:factor(Gendering)1 0.12987 0.10544 1.232 0.22030
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.916 on 129 degrees of freedom
Multiple R-squared: 0.04265, Adjusted R-squared: 0.02039
F-statistic: 1.916 on 3 and 129 DF, p-value: 0.1303
We observe that the estimations between age and gender are not significant.
b) How strong is the predictive power of this model?
Looking at the adjusted R square we can see that the effect of age combined with the effect of gender explains 1,6% the variability of the score - when doing multiple regression, adjusted R squared is a better indication to look at for the predictive power of the models. And in conclusion, this one does not have a strong predictive power.
c) What is the predicted outcome for a 20 year old man? 20 year old woman? 40 year old man? 40 year old woman?
Following similar procedure as the exercise 1 and 2 c, we substitute the age and gender factors in the equation for the equivalent results we need in the four different instances:
#for 20year old mantwentyman <-0.02*20-1.1*1+4.08#for 20year old womantwentywoman <-0.02*20-1.1*0+4.08#for 40year old manfourtyman <-0.02*40-1.1*1+4.08#for 40year old womanfourtywoman <-0.02*40-1.1*0+4.08
As we can see, the predicted scores are the following:
for 20year old man = 3.38